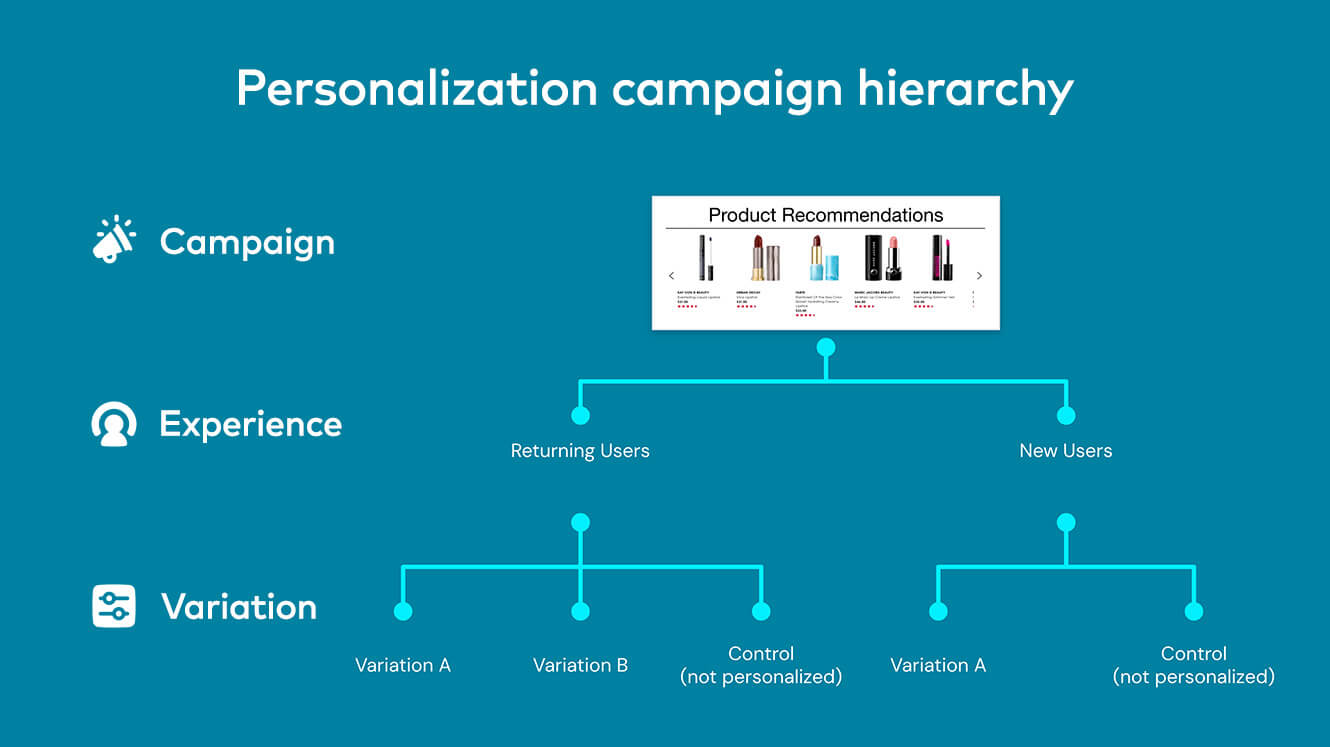
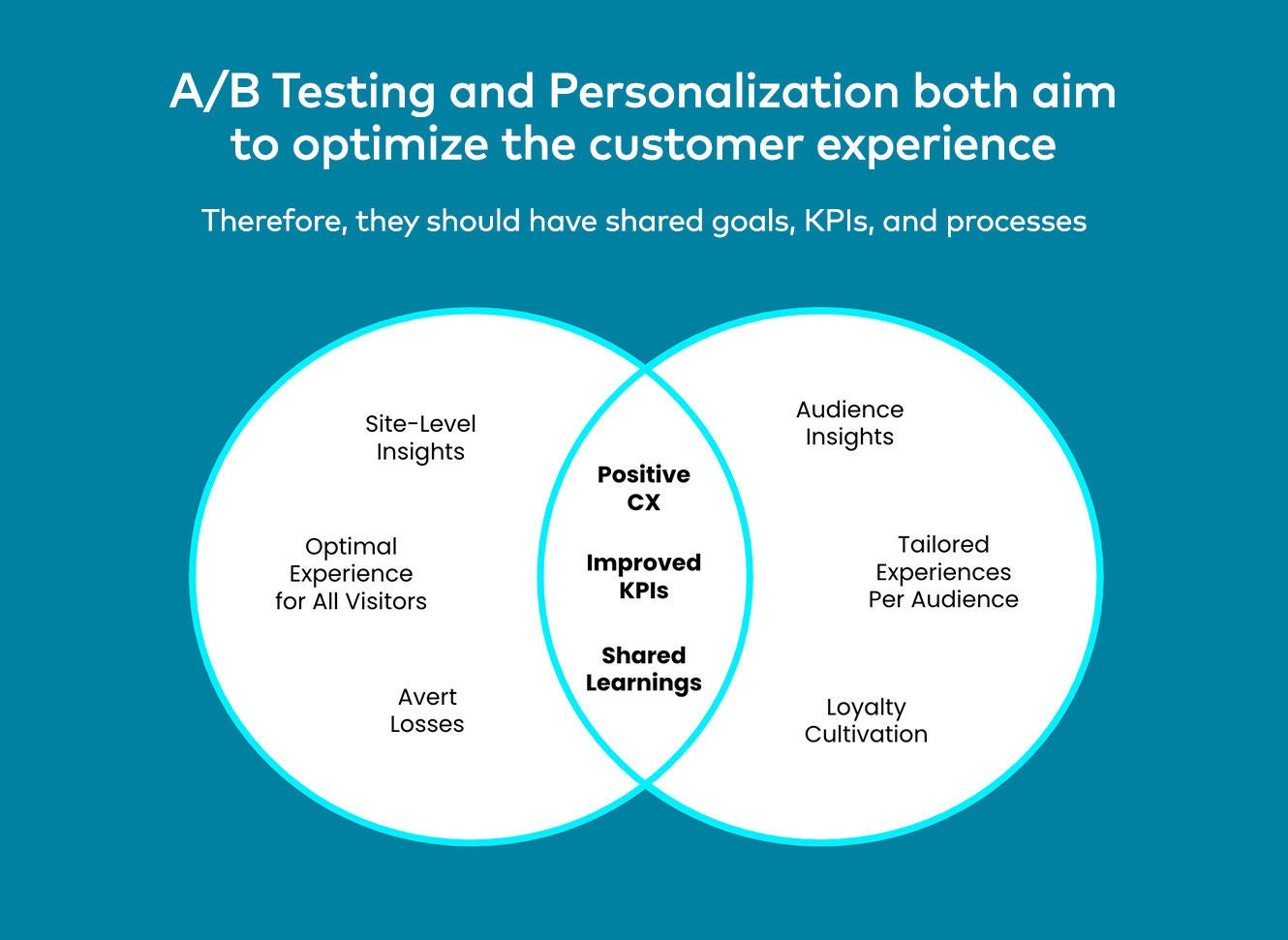
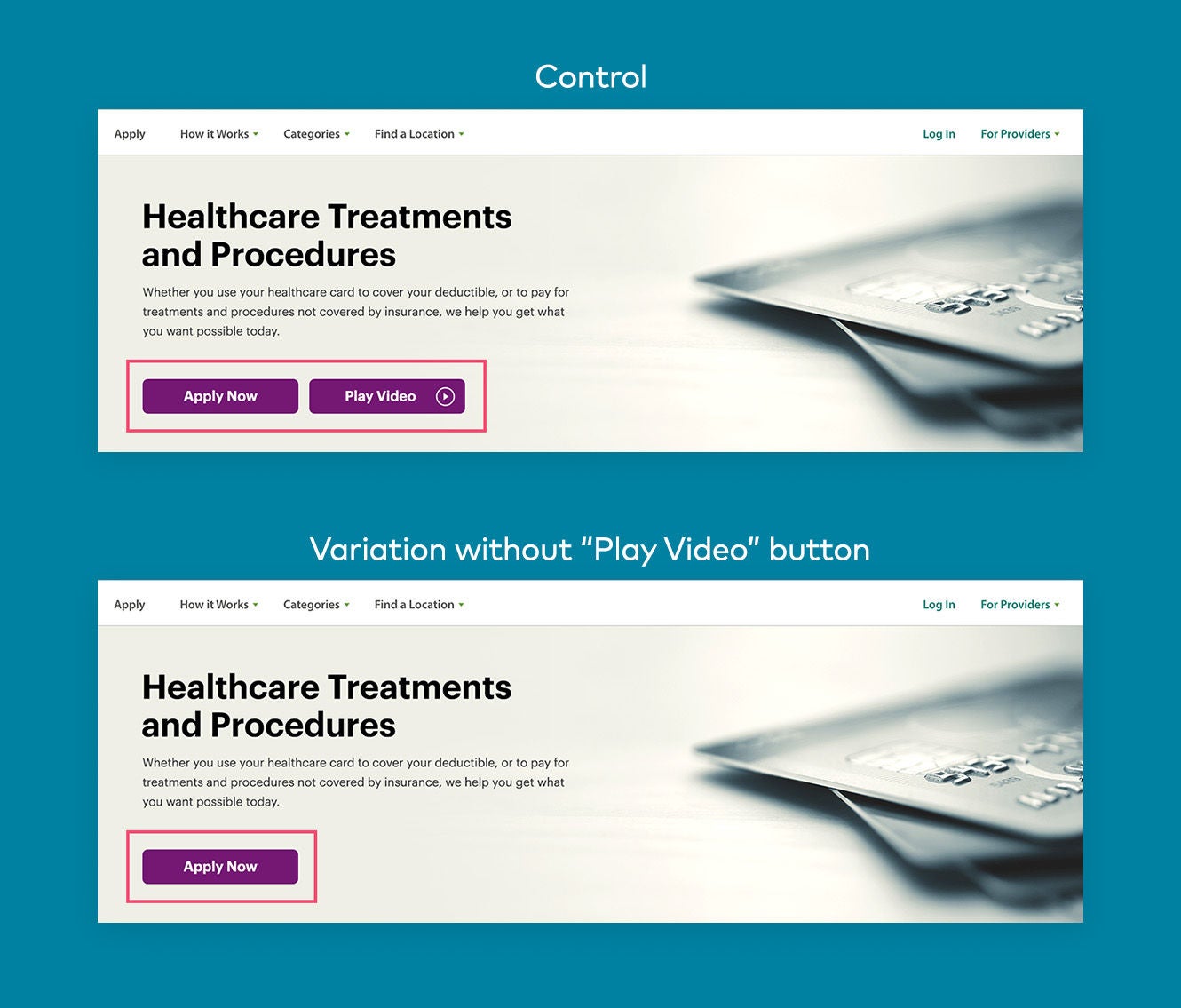
La premisa de las pruebas A/B es simple:
Compare dos (o más) versiones diferentes de algo para ver cuál funciona mejor y luego implemente la ganadora para todos los usuarios para obtener la experiencia general más óptima.
Por lo tanto, la práctica de los equipos de pruebas A/B y CRO ha sido invertir significativamente en el lanzamiento de todo tipo de experimentos para mejorar diferentes áreas y experiencias en el sitio, la aplicación nativa, el correo electrónico o cualquier otro canal digital y luego optimizarlos continuamente para impulsar un aumento incremental en las conversiones y los KPI específicos a medida que pasa el tiempo.
Sin embargo, a menos que una empresa genere toneladas de tráfico y tenga un enorme panorama digital desde el cual experimentar, puede llegar un punto de rendimientos decrecientes donde el resultado de la experimentación (sin importar cuántas pruebas o cuán grande y sofisticado pueda ser el experimento) alcance un rendimiento máximo en términos del aporte de estos equipos.
Esto tiene que ver en gran medida con el hecho de que el enfoque clásico de las pruebas A/B ofrece una visión binaria de las preferencias de los visitantes y a menudo no logra capturar la gama completa de factores y comportamientos que los definen como individuos.
Además, las pruebas A/B producen resultados generalizados basados en las preferencias mayoritarias de un segmento. Y si bien una marca puede descubrir que una experiencia particular produce más ingresos en promedio, implementarla para todos los usuarios sería un perjuicio para una porción significativa de consumidores con preferencias diferentes.
Permítanme ilustrarlo con algunos ejemplos:
Si el patrimonio neto tanto mío como de Warren Buffet fuera de 117,3 mil millones de dólares en promedio, ¿tendría sentido recomendarnos los mismos productos?
Probablemente no.
¿O qué sucede si un minorista que ofrece productos tanto para hombres como para mujeres decide realizar una prueba A/B clásica en su página de inicio para identificar la variación de banner principal con mejor rendimiento, pero como el 70 % de su audiencia son mujeres, la variación para mujeres supera a la para hombres?
Esta prueba sugeriría que la etiqueta de heroína femenina se aplicara a toda la población, pero seguramente no sería la decisión correcta.
En pocas palabras:
- Los promedios suelen ser engañosos cuando se utilizan para comparar diferentes grupos de usuarios.
- Los cambios de variación con mejor rendimiento para cada segmento de cliente y usuario
- Los resultados también pueden verse influenciados por factores contextuales como la geografía, el clima y más.
Esto no quiere decir, por supuesto, que no haya un momento y un lugar para aprovechar resultados más generalizados. Por ejemplo, si estuviera probando el diseño de un nuevo sitio web o una nueva aplicación, tendría sentido apuntar a una interfaz de usuario consistente que funcionara mejor en promedio, en lugar de docenas, cientos o incluso miles de variaciones de interfaz de usuario para diferentes usuarios.
Sin embargo, los días de adoptar fielmente un enfoque de "el ganador se lo lleva todo" para el diseño de una página, mensajes, contenido, recomendaciones, ofertas y otros elementos creativos han terminado, y eso está bien porque significa que ya no se perderá dinero por las oportunidades de personalización perdidas asociadas con no ofrecer la mejor variación a cada usuario individual.