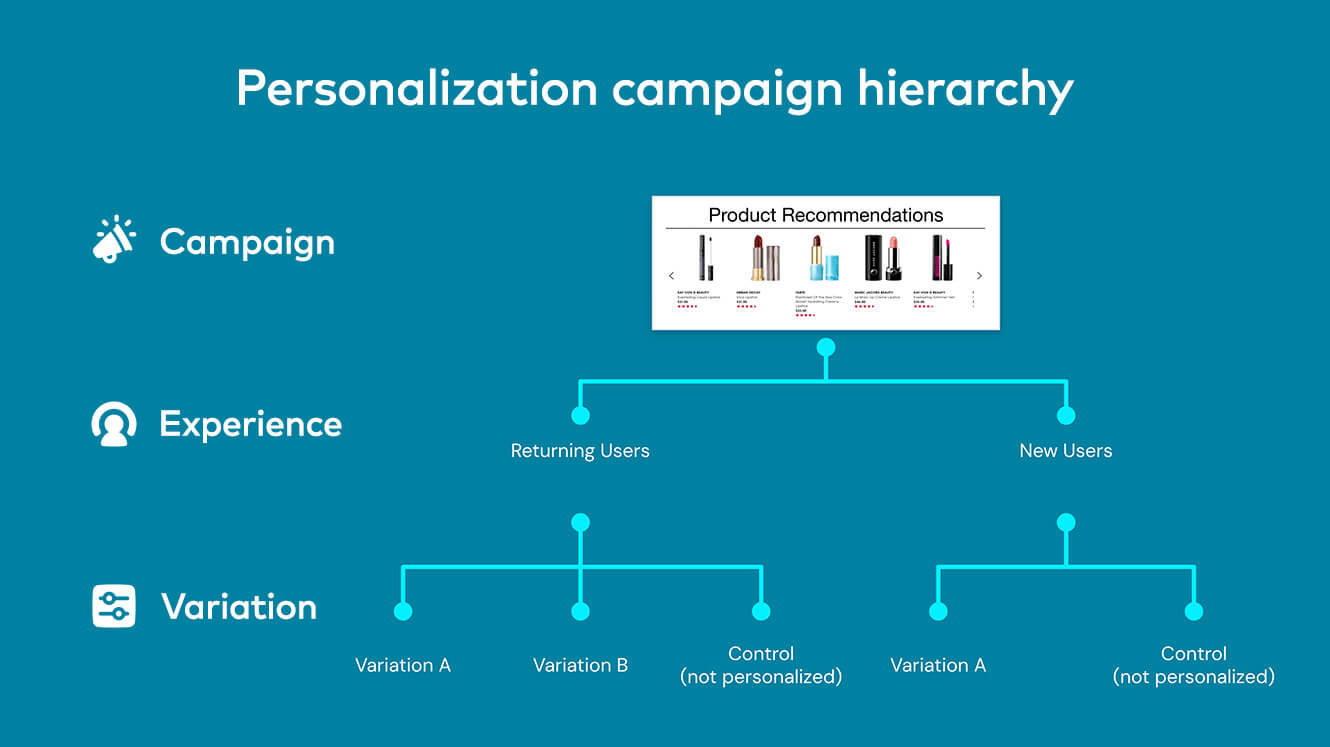
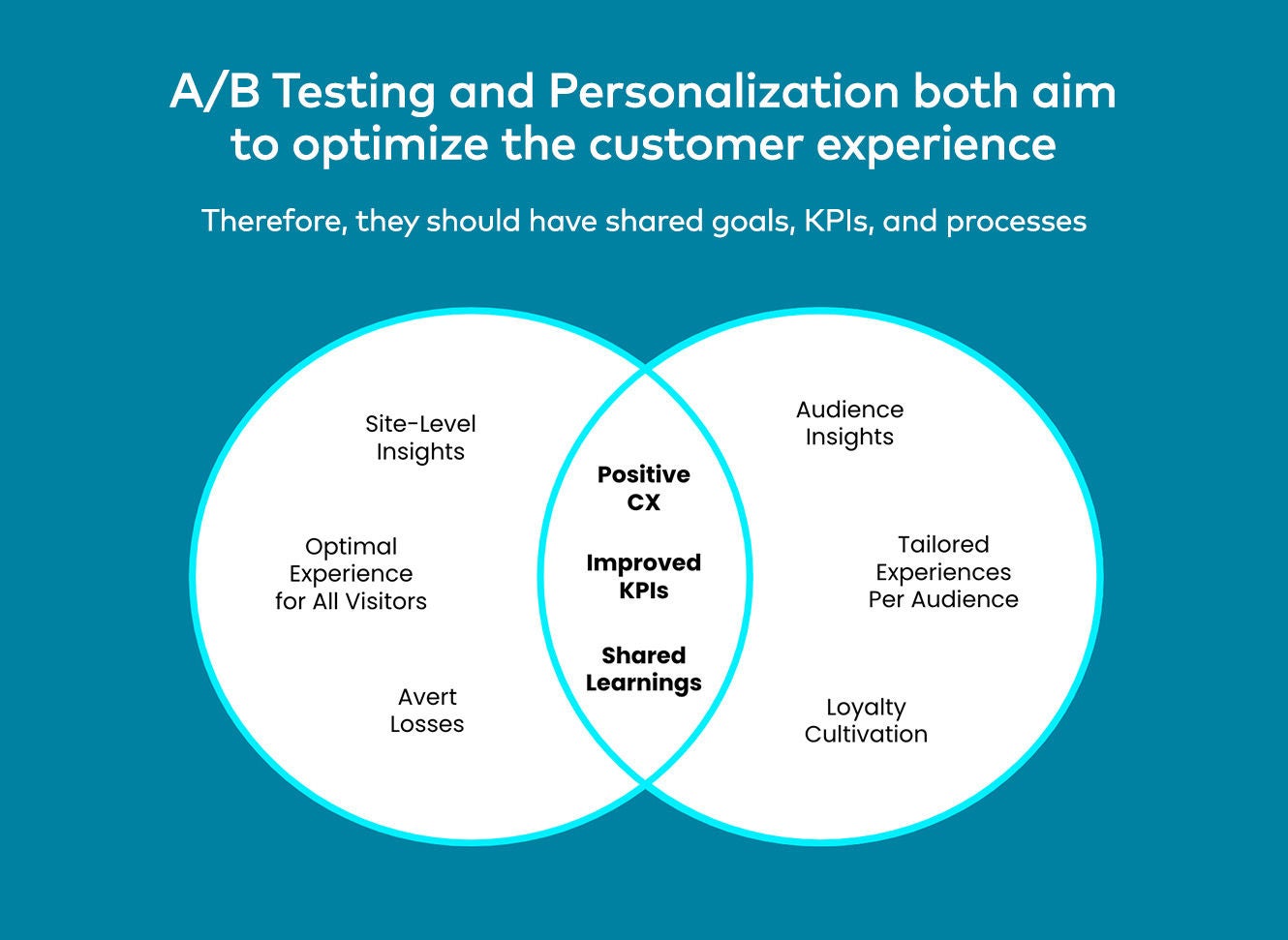
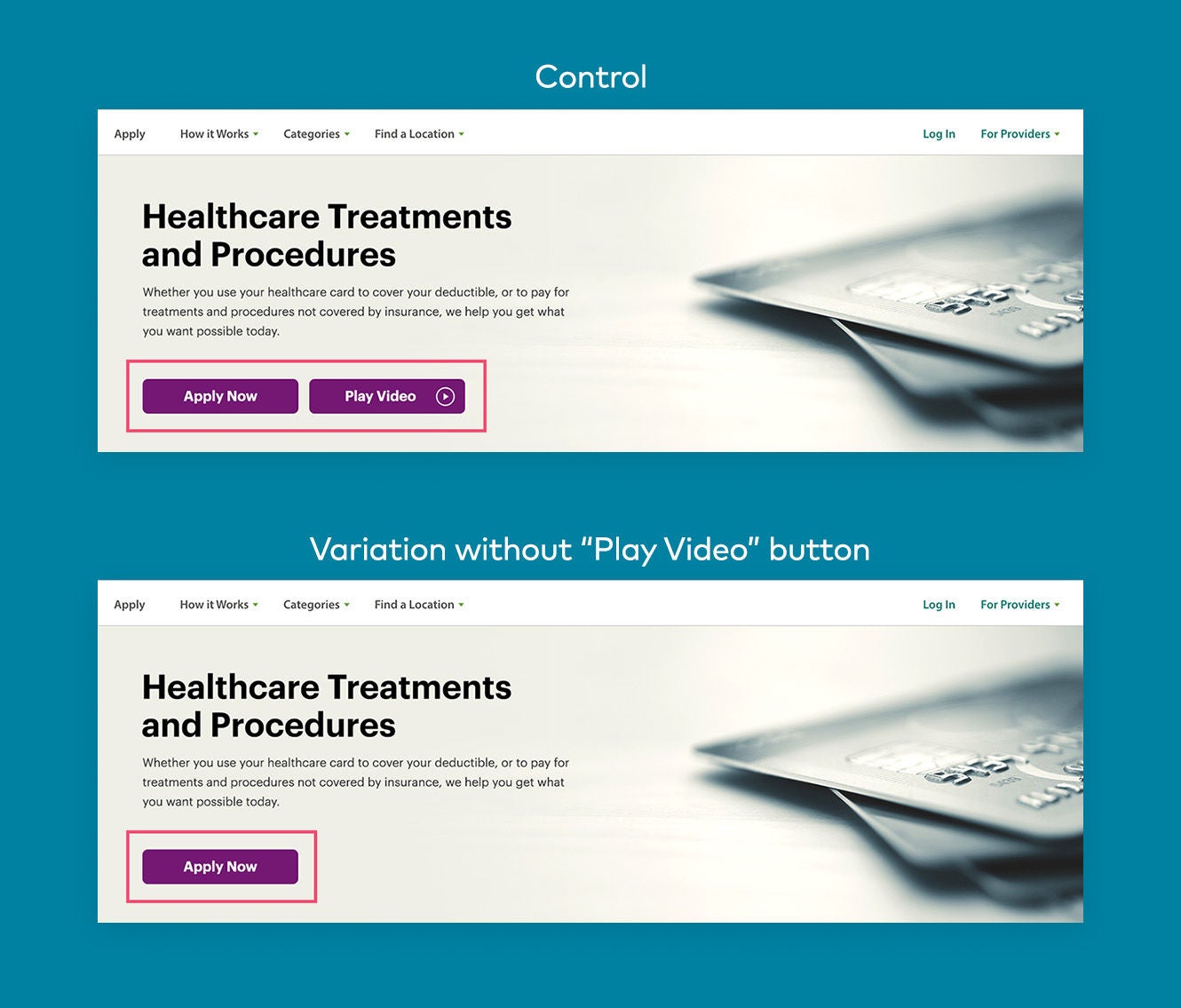
Le principe des tests A/B est simple :
Comparer deux (ou plusieurs) versions différentes d'un produit pour voir laquelle est la plus performante, puis déployer la version gagnante pour tous les utilisateurs afin d'optimiser l'expérience globale.
La pratique des tests A/B et des équipes CRO a donc consisté à investir considérablement dans le lancement de toutes sortes d'expériences pour améliorer différents domaines et expériences sur le site, l'application native, l'e-mail ou tout autre canal numérique, puis à les optimiser en permanence pour obtenir une augmentation incrémentale des conversions et des indicateurs clés de performance spécifiques au fil du temps.
Toutefois, à moins qu'une entreprise ne génère des tonnes de trafic et ne dispose d'un immense paysage numérique à partir duquel expérimenter, il peut arriver un point de rendement décroissant où le résultat de l'expérimentation (quel que soit le nombre de tests ou l'ampleur et la sophistication d'une expérience) atteint un rendement maximal en termes d'apport de ces équipes.
Cela s'explique en grande partie par le fait que l'approche classique des tests A/B offre une vision binaire des préférences des visiteurs et ne parvient souvent pas à saisir l'ensemble des facteurs et des comportements qui les définissent en tant qu'individus.
De plus, les tests A/B donnent des résultats généralisés basés sur les préférences majoritaires d'un segment. Et si une marque peut trouver qu'une expérience particulière génère plus de revenus en moyenne, la déployer pour tous les utilisateurs serait un mauvais service rendu à une grande partie des consommateurs qui ont des préférences différentes.
Permettez-moi d'illustrer mon propos par quelques exemples :
Si mon patrimoine et celui de Warren Buffet s'élevaient en moyenne à 117,3 milliards de dollars, serait-il logique de nous recommander les mêmes produits ?
Probablement pas.
Ou encore, un détaillant qui propose des produits pour hommes et pour femmes décide d'effectuer un test A/B classique sur sa page d'accueil afin d'identifier la variante de bannière héroïque la plus performante, mais comme 70% de son public est composé de femmes, la variante pour femmes est plus performante que celle pour hommes.
Ce test suggérerait que la bannière du héros des femmes soit appliquée à l'ensemble de la population, mais ce ne serait certainement pas la bonne décision.
Pour faire simple :
- Les moyennes sont souvent trompeuses lorsqu'elles sont utilisées pour comparer différents groupes d'utilisateurs.
- La variation la plus performante change pour chaque segment de clientèle et chaque utilisateur.
- Les résultats peuvent également être influencés par des facteurs contextuels tels que la géographie, la météo, etc.
Cela ne veut pas dire, bien sûr, qu'il n'y a pas un temps et un lieu pour tirer parti de résultats plus généraux. Par exemple, si vous testez la conception d'un nouveau site web ou d'une nouvelle application, il serait logique de viser une interface utilisateur cohérente qui fonctionne le mieux en moyenne, plutôt que des dizaines, des centaines, voire des milliers de variations de l'interface utilisateur pour différents utilisateurs.
Cependant, l'époque où l'on adoptait fidèlement une approche "gagnant-gagnant" pour la mise en page, les messages, le contenu, les recommandations, les offres et autres éléments créatifs est révolue - et c'est tant mieux, car cela signifie que l'on ne laissera plus d'argent sur la table en raison des opportunités de personnalisation manquées associées au fait de ne pas proposer la meilleure variation à chaque utilisateur individuel.