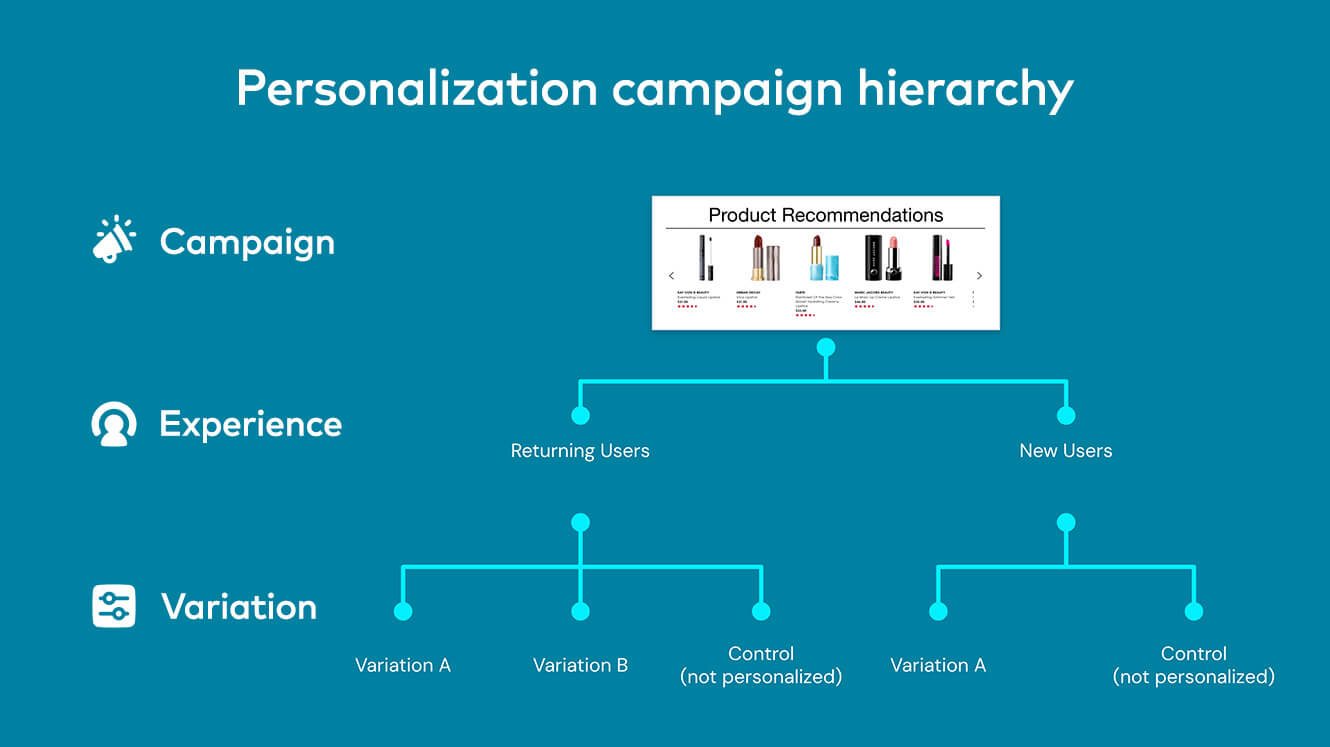
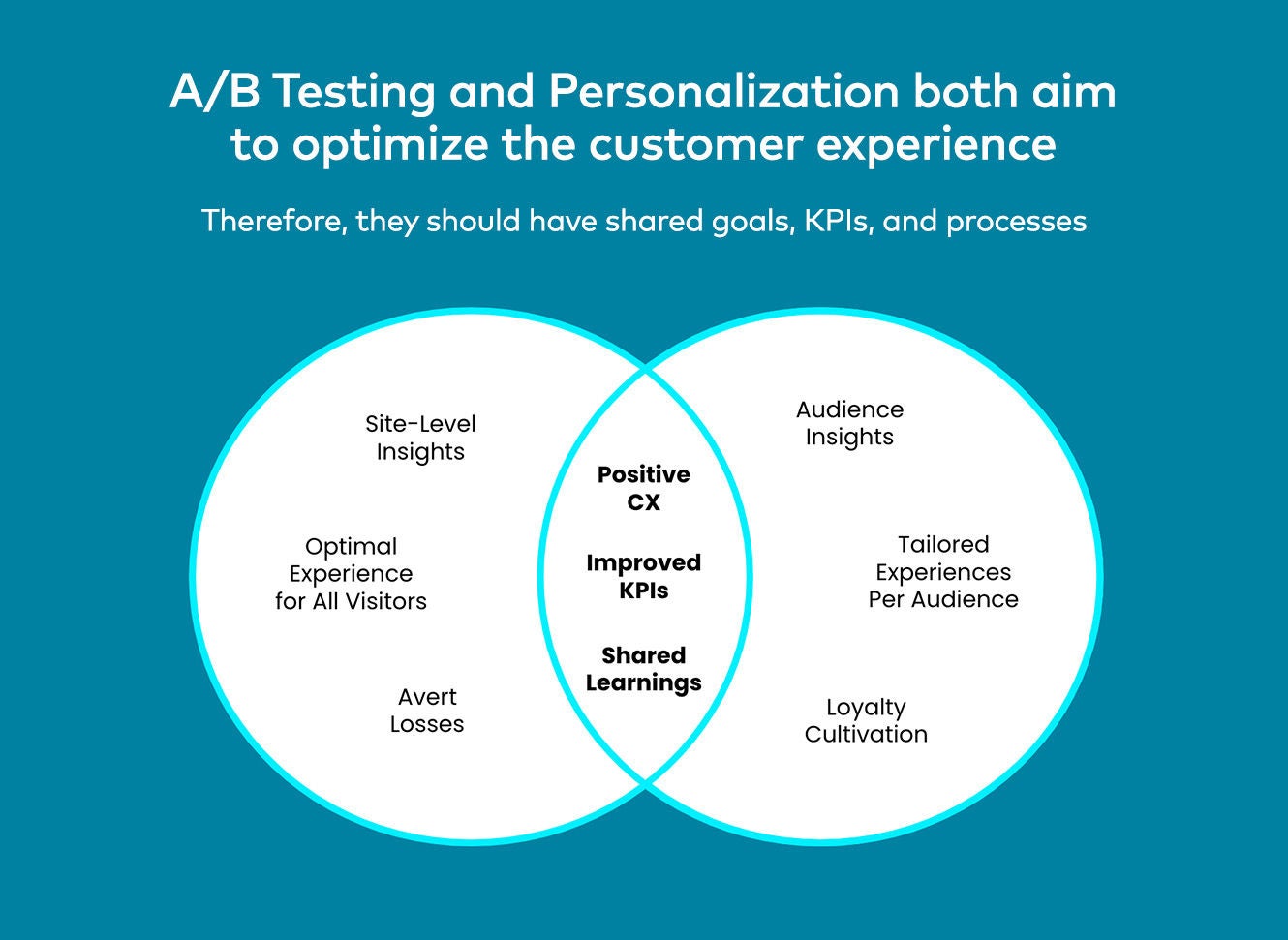
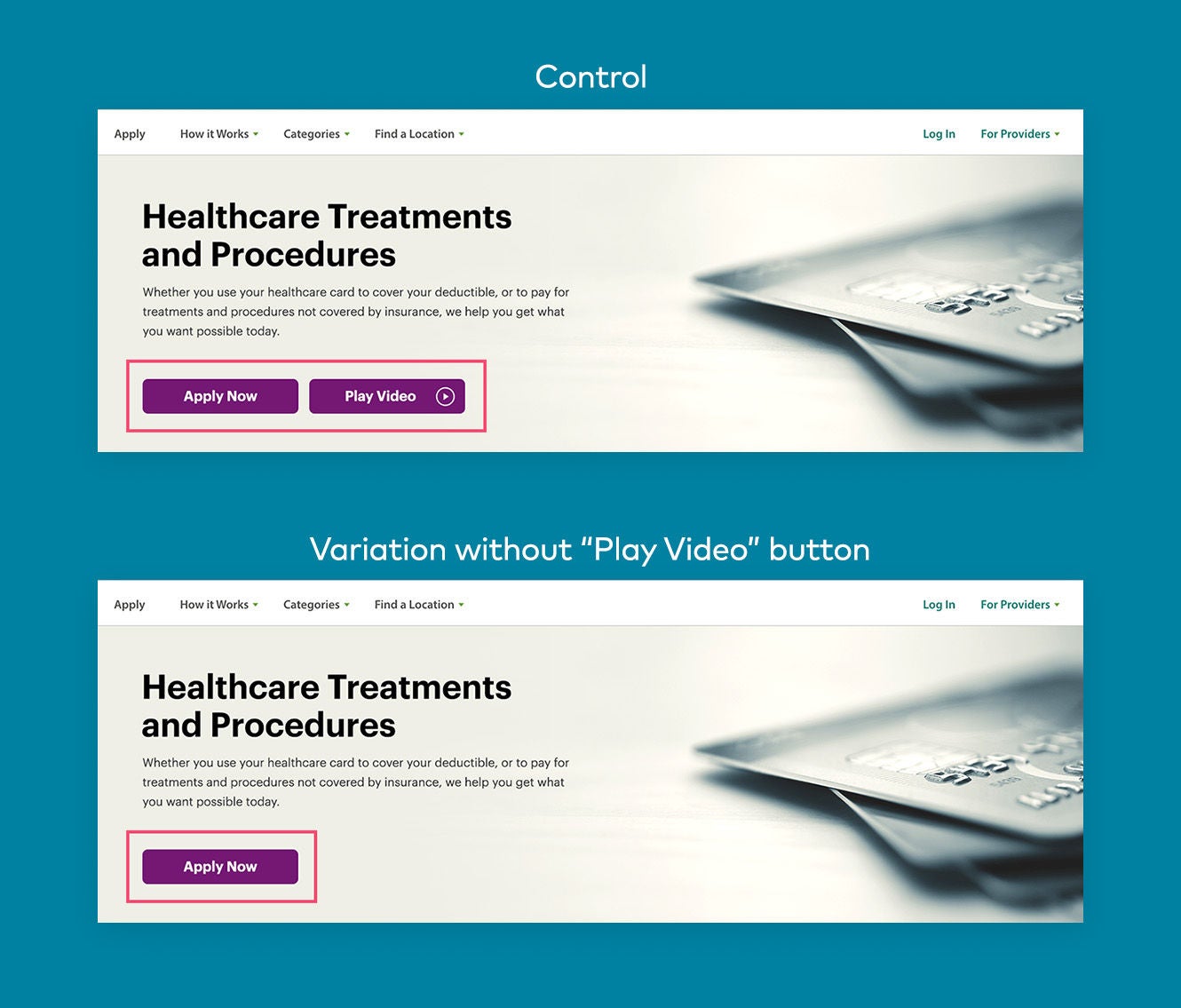
Het uitgangspunt van A/B-testen is eenvoudig:
Vergelijk twee (of meer) verschillende versies van iets om te zien welke beter presteert en implementeer vervolgens de winnaar voor alle gebruikers voor de meest optimale algehele ervaring.
De praktijk van A/B-test- en CRO-teams is dus om aanzienlijk te investeren in het lanceren van allerlei experimenten om verschillende gebieden en ervaringen op de site, native app, e-mail of een ander digitaal kanaal te verbeteren en deze vervolgens continu te optimaliseren om in de loop van de tijd een incrementele toename van conversies en specifieke KPI's te stimuleren.
Tenzij een bedrijf echter tonnen verkeer genereert en een enorm digitaal landschap heeft om te experimenteren, kan er een punt van afnemende opbrengsten komen waarop de output van experimenten (ongeacht hoeveel tests of hoe groot en geavanceerd een experiment ook is) een maximale opbrengst bereikt in termen van de input van deze teams.
Dit heeft grotendeels te maken met het feit dat de klassieke benadering van A/B-testen een binair beeld biedt van de voorkeuren van bezoekers en er vaak niet in slaagt het volledige scala aan factoren en gedrag vast te leggen die bepalen wie ze zijn als individuen.
Bovendien leveren A/B-tests gegeneraliseerde resultaten op op basis van de meerderheidsvoorkeuren van een segment. En hoewel een merk een bepaalde ervaring gemiddeld meer inkomsten kan opleveren, zou het een slechte dienst zijn om deze voor alle gebruikers in te zetten voor een aanzienlijk deel van de consumenten met andere voorkeuren.
Laat me dit illustreren met een paar voorbeelden:
Als het vermogen van zowel mijzelf als Warren Buffet gemiddeld $ 117.3 miljard USD zou zijn, zou het dan zinvol zijn om dezelfde producten aan ons aan te bevelen?
Waarschijnlijk niet.
Of wat dacht je ervan als een detailhandelaar die zowel heren- als damesproducten serveert, besluit een klassieke A/B-test op hun homepage uit te voeren om de best presterende hero-bannervariant te identificeren, maar aangezien 70% van hun publiek uit vrouwen bestaat, presteert de vrouwenvariant beter dan de mannenvariant.
Deze test zou suggereren dat de heldenvlag van de vrouw op de hele bevolking wordt toegepast, maar het zou zeker niet de juiste beslissing zijn.
Simpel gezegd:
- Gemiddelden zijn vaak misleidend wanneer ze worden gebruikt om verschillende gebruikersgroepen te vergelijken
- De best presterende variant verandert voor elk klantsegment en elke gebruiker
- Resultaten kunnen ook worden beïnvloed door contextuele factoren zoals geo, weer en meer
Dit wil natuurlijk niet zeggen dat er geen tijd en plaats is om meer algemene resultaten te gebruiken. Als je bijvoorbeeld een nieuwe website of app aan het testen bent, zou het zinvol zijn om te streven naar één consistente UI die gemiddeld het beste werkt in plaats van tientallen, honderden of zelfs duizenden UI-variaties voor verschillende gebruikers.
De dagen van trouw een "winner-take-all"-benadering van de lay-out van een pagina, berichten, inhoud, aanbevelingen, aanbiedingen en andere creatieve elementen zijn echter voorbij - en dat is oké, want het betekent dat er niet langer geld op tafel blijft liggen voor de gemiste personalisatiemogelijkheden die gepaard gaan met het niet leveren van de beste variatie aan elke individuele gebruiker.