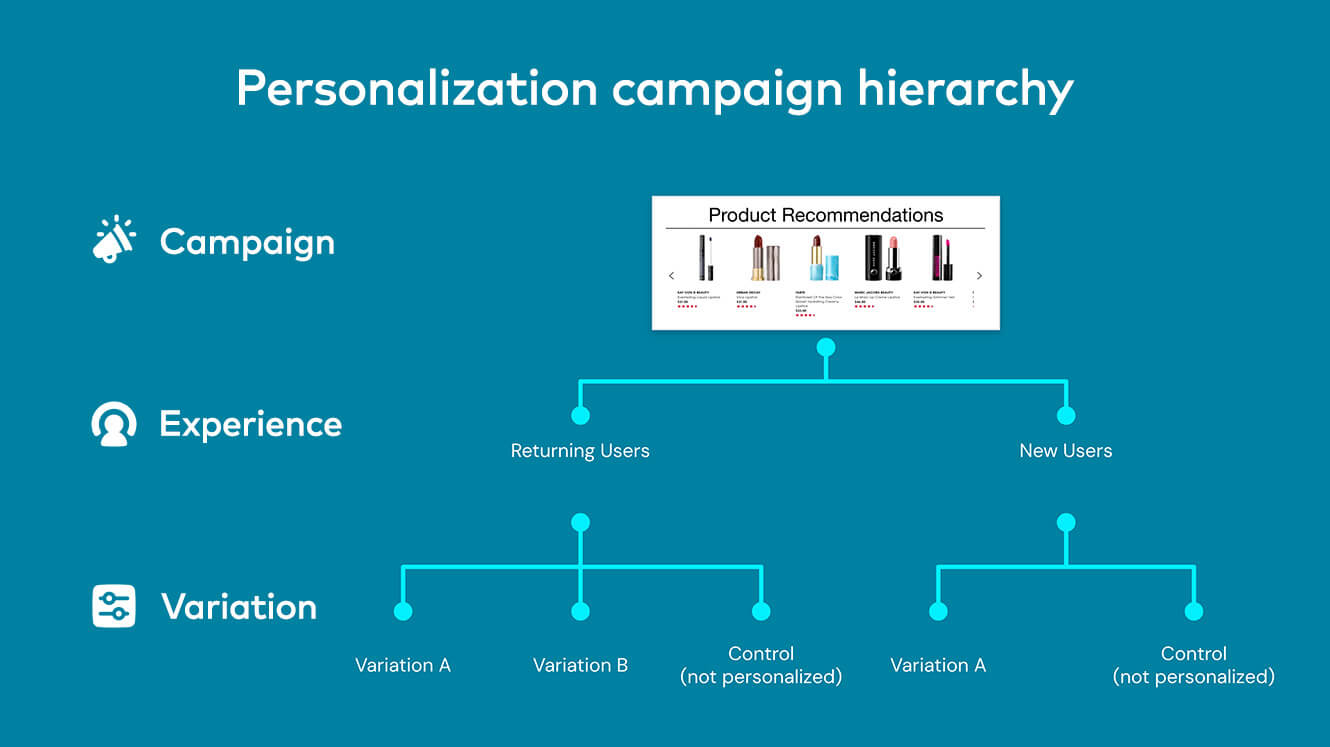
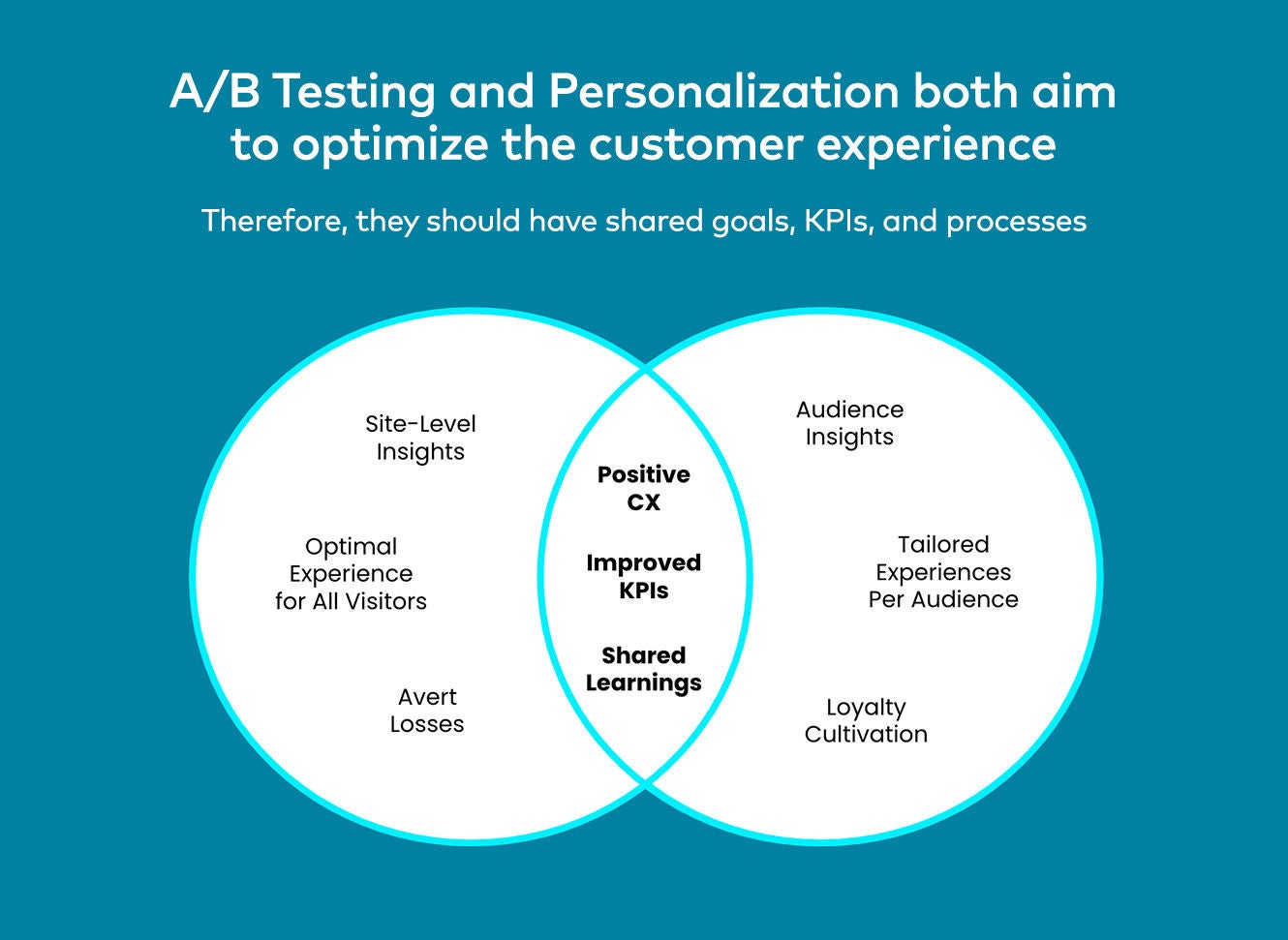
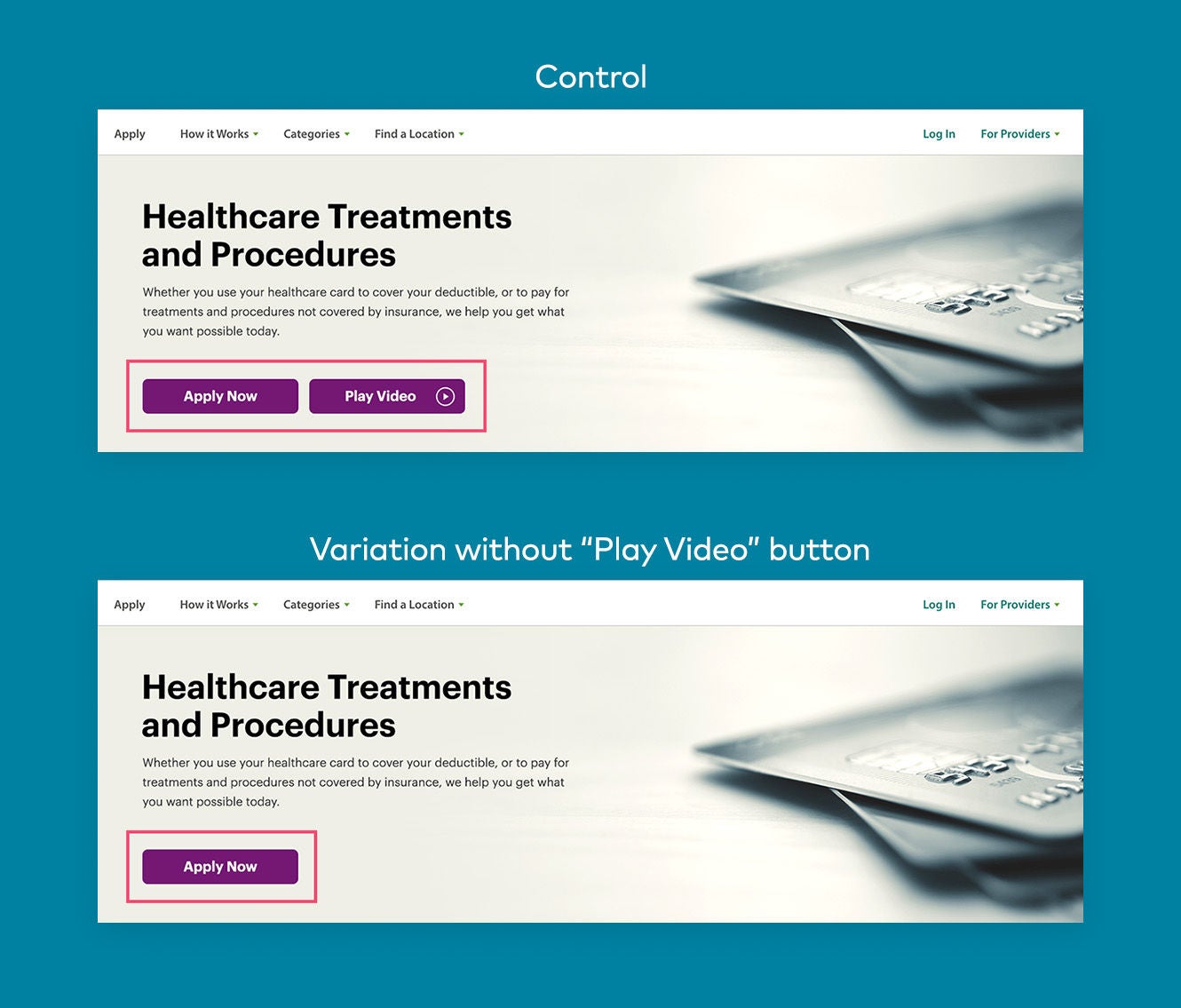
Præmissen bag A/B-testning er enkel:
Sammenlign to (eller flere) forskellige versioner af noget for at se, hvilken der klarer sig bedst, og distribuer derefter vinderen til alle brugere for at opnå den mest optimale samlede oplevelse.
Praksissen for A/B-test- og CRO-teams har derfor været at investere betydeligt i at lancere alle mulige slags eksperimenter for at forbedre forskellige områder og oplevelser på tværs af webstedet, native apps, e-mails eller andre digitale kanaler og derefter løbende optimere dem for at drive en gradvis stigning i konverteringer og specifikke KPI'er over tid.
Men medmindre en virksomhed genererer tonsvis af trafik og har et enormt digitalt landskab at eksperimentere fra, kan der komme et punkt med aftagende afkast, hvor outputtet af eksperimentering (uanset hvor mange tests eller hvor stort og sofistikeret et eksperiment måtte være) når et maksimalt udbytte med hensyn til input fra disse teams.
Dette hænger i høj grad sammen med, at den klassiske tilgang til A/B-testning tilbyder et binært overblik over de besøgendes præferencer og ofte ikke formår at indfange hele spektret af faktorer og adfærd, der definerer, hvem de er som individer.
Derudover giver A/B-tests generaliserede resultater baseret på et segments majoritetspræferencer. Og selvom et brand måske oplever, at en bestemt oplevelse i gennemsnit giver mere omsætning, ville det være en bjørnetjeneste for en betydelig del af forbrugerne med forskellige præferencer at implementere den til alle brugere.
Lad mig illustrere med et par eksempler:
Hvis både min og Warren Buffets nettoformue i gennemsnit var 117,3 milliarder USD, ville det så give mening at anbefale de samme produkter til os?
Sandsynligvis ikke.
Eller hvad nu hvis en detailhandler, der tilbyder både herre- og dameprodukter, beslutter sig for at køre en klassisk A/B-test på deres hjemmeside for at identificere den bedst performende hero-bannervariant, men da 70 % af deres målgruppe er kvinder, klarer kvindernes variant sig bedre end mændenes.
Denne test ville antyde, at kvindernes heltebanner skulle anvendes på hele befolkningen, men det ville bestemt ikke være den rigtige beslutning.
For at sige det enkelt:
- Gennemsnit er ofte misvisende, når de bruges til at sammenligne forskellige brugergrupper
- De bedst performende variationsændringer for hvert kundesegment og bruger
- Resultaterne kan også påvirkes af kontekstuelle faktorer som geografi, vejr og mere
Det betyder selvfølgelig ikke, at der ikke er tid og sted til at udnytte mere generaliserede resultater. Hvis du for eksempel testede et nyt website- eller appdesign, ville det give mening at sigte mod én ensartet brugergrænseflade, der fungerede bedst i gennemsnit, sammenlignet med snesevis, hundredvis eller endda tusindvis af brugergrænsefladevariationer for forskellige brugere.
Men dagene med trofast at have en "vinderen tager det hele"-tilgang til layout af en side, beskeder, indhold, anbefalinger, tilbud og andre kreative elementer er forbi – og det er okay, for det betyder, at der ikke længere vil være penge tilbage på bordet fra de mistede personaliseringsmuligheder, der er forbundet med ikke at levere den bedste variation til hver enkelt bruger.